HBase
- Feb 1, 2015
- 7 min read
Note: This is created for hands-on. Detailed notes will be added soon…
Apache HBase is one such system. It is an open source distributed database, modeled around Google Bigtable and is becoming an increasingly popular database choice for applications that need fast random access to large amounts of data.
HBase is a Key/Value store. HBase uses HDFS for storage. As described in the original Bigtable paper, it’s a sparse, distributed, persistent multidimensional sorted map, which is indexed by a row key, column key, and a timestamp.
HBase is,
Sparse – in real time, lot of data is not provided (some fields may be empty). Opposite to sparse is dense data (where all fields are completely available, like POS data)
Distributed – split the data and maintain in multiple servers
Multi dimensional
Sorted Map – for quick search
Consistent (This is the only difference between Cassandra and HBase. Where earlier supports availability)
Linear
Automatic Sharding – Horizontal splitting of data
Table: HBase organizes data into tables. Table names are Strings and composed of characters that are safe for use in a file system path.
Row: Within a table, data is stored according to its row. Rows are identified uniquely by their row key. Row keys do not have a data type and are always treated as a byte[ ] (byte array).
Column Family: Data within a row is grouped by column family. Column families also impact the physical arrangement of data stored in HBase. For this reason, they must be defined up front and are not easily modified. Every row in a table has the same column families, although a row need not store data in all its families. Column families are Strings and composed of characters that are safe for use in a file system path.
Column Qualifier: Data within a column family is addressed via its column qualifier, or simply, column. Column qualifiers need not be specified in advance. Column qualifiers need not be consistent between rows. Like row keys, column qualifiers do not have a data type and are always treated as a byte[ ].
Cell: A combination of row key, column family, and column qualifier uniquely identifies a cell. The data stored in a cell is referred to as that cell’s value. Values also do not have a data type and are always treated as a byte[ ].
Timestamp: Values within a cell are versioned. Versions are identified by their version number, which by default is the timestamp of when the cell was written. If a timestamp is not specified during a write, the current timestamp is used. If the timestamp is not specified for a read, the latest one is returned. The number of cell value versions retained by HBase is configured for each column family. The default number of cell versions is three

Column family – group similar columns under a column
When to use HBase:
Unstructured data
High Scalability – Horizontal Scalability with HBase
Versioned data – Can handle up to 3 latest versions based on time stamp
High Volume data to be stored
Column oriented data
Generating data from MR work flow
When not to use HBase:
When the data is low, i.e data is only a few thousand/million rows
Lacks RDBMS commands
When you have hardware less that 5 data nodes, when replication factor is 3
HBase Users:
Popular companies using HBase,
Twitter – A number of applications including people search rely on HBase internally for data generation
Facebook – Uses HBase to power their message infrastructure
Facebook monitors their usage and figured out what the really needed. What they have actual needed was a system that could handle two types of data patterns:
A short set of temporal data that tends to be volatile.
An ever-growing set of data that rarely get accessed.
Stumble Upon – Use HBase as a real time data storage and analytics platform
Yahoo – Uses HBase to store document fingerprint for detecting near-duplications. We have a cluster of few nodes that run HDFS, mapreduce and HBase
Explorys – Uses an HBase cluster containing over a billion anonymized clinical records
Trend Micro – Uses HBase as a foundation for cloud scale storage for a variety of applications
Key is formed by [row key, column family, column qualifier, timestamp] and Value is the contents of the cell.
Hands-On
Enter “JPS” in terminal and check for the process HMaster. If it is not running go to bin library in HBase and type start-hbase.sh in the shell and enter.
hbase shell – to login to hbase shell
Quit – to quit
List – to show list of tables
Create – To Create a table
Create employee table using above commands:
Create ‘employee’, ‘personal’
‘Put ‘employee’,’emp1’,’personal:name’,’kishore’
Put ‘employee’,’emp1’,’personal:age’,’32’
Put ‘employee’,’emp1’,’personal:password’,’abc123’
Scan ‘employee’
Get ‘employee’, ‘emp1’
Let’s update the password and see how it will works
Put ‘employee’,’emp1’,’personal:password’,’abc234’
Get ‘employee’, ‘emp1’
Observe the timestamp for the difference after the above command
To check version of the updated password field, enter below command
Get ‘employee’, ‘emp1’,{column=>’personal:password’,VERSIONS=>2}
To get value for specific value which are having multiple versions
Get ‘employee’,’emp1’{COLUMN=>’personal:password’,TIMESTAMP=>1234566789}
Table->Row key->Column Family->Column->Timestamp
Emp1 (row key) is hashmap of column family (Personal (key)) and its columns (name, age, password (values))
Personal (column family) is the hashmap of column (name(key)) and its data (Kishore (value)). Similarly for age and password.
Name (column) is the hashmap of timestamp (key) and data (value)
Now create another column family address.
Disable ‘employee’
Alter ‘employee’,{NAME=>’address’}
Enable ‘employee’
Put ‘employee’,’emp1’,’address:street’,’5th cross’
Put ‘employee’,’emp1’,’address:city’,’hyderabad’
Put ‘employee’,’emp1’,’address:state’,’Telangana’
Scan ‘employee’
Now if you observe, the address will retrieve on the top. This means the data is sorted.
Create multiple columns
Create ‘t1’,{NAME=>CF1},{NAME=>’CF2’}
To delete any column, we need to disable the table.
Disable ‘employee’
Alter ‘employee’,{NAME=>’address’, METHOD=>’delete’}
Check whether column is deleted
Enable ‘employee’
Scan ‘employee’
Is enabled ‘employee’ # check whether table is enable or not
Count ‘employee’ # To get the row count
Scan ‘employee’,{LIMIT=>10} # To limit the number of records returned
Delete ‘employee’,’emp1’,’personal:age’ # to delete specific value
Scan ‘employee’
To convert date time to the timestamp, import java.util.Date
Import java.util.Date
new(123456789).toString()
Data Model:
Table schema only defines its column families
Consists of any number of columns
Consists of any number of versions (by default 3)
Columns exist when inserted (columns will add on the fly)
Columns in a family are sorted & stored together
HBase write path: How it writes internally to HDFS
When client writes data, it will write to 2 places simultaneously to maintain data durabality
WAL (Write ahead Log)/HLog
Memstore
Memstore is a write buffer, where HBase accumulates all the data before it writes permanently to disk. When Memstore fills up, its contents are placed to the disk as a new HFile.
Each HFile belongs to one particular column family (they won’t maintain multiple column families in same HFile). One column family has multiple HFiles and one Memstore is assigned for one column family.
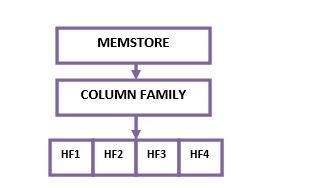
HFile block size by default is 64kb.
Client doesn’t directly interact with HFile.
HBase Read Path: Data is reconciled from the BlockCache, the Memstore and the HFiles to give the client and up-to-date view of the rows it asked for.
All Region Servers are run in data nodes which are having multiple Regions. Each Region has column family based Memstore, WAL, block cache and HFiles.
In Hbase we can have multiple masters. One master is active and the rest will passive.
HMaster will assign regions to region servers. It also maintains 2 tables ROOT and META. ROOT will have information of META tables. META table has all the information of Region Servers. All active and passive HMaster will maintain same data all the time (there is no periodic sync like happens between NN and SNN).
Zookeeper will handle the co-ordination between master and region servers. It also handle electing the masters.
1 Region size is 256 MB, so there are 4096 HFiles in each region.
Configure hbase.hregion.max.filesize (upper limit of region size to 4GB) in Hbase-site.xml
HBase components:
Table made of regions
Region – a range of rows sorted together
Region servers – serves one or more regions
A region is served by only one regions server
Master server – daemon responsible for managing HBase cluster
HBase stores its data into HDFS
Relies on HDFS’s high availability and fault tolerance
Compactions (Consolidation):
HBase writes out immutable files as data is added
Each store consists of rowkey-ordered files
Immutable – More files accumulate over time
Compaction rewrites several files into one
Lesser files – faster reads
Major compaction rewrites all files in a store into one
Can drop deleted records and old versions
In a minor compaction, files to compact are selected based on a heuristic
Important points to remember:
Row keys are the single most important aspect of an HBase table design and determine how your application will interact with the HBase tables. They also affect the performance you can extract out of HBase.
HBase tables are flexible, and you can store anything in the form of byte[ ].
Store everything with similar access patterns in the same column family.
Indexing is only done for the Keys. Use this to your advantage.
Tall tables can potentially allow you faster and simpler operations, but you trade off atomicity. Wide tables, where each row has lots of columns, allow for atomicity at the row level.
Think how you can accomplish your access patterns in single API calls rather than multiple API calls. HBase does not have cross-row transactions, and you want to avoid building that logic in your client code.
Hashing allows for fixed length keys and better distribution but takes away the ordering implied by using strings as keys.
Column qualifiers can be used to store data, just like the cells themselves.
The length of the column qualifiers impact the storage footprint since you can put data in them. Length also affects the disk and network I/O cost when the data is accessed. Be concise.
The length of the column family name impacts the size of data sent over the wire to the client (in KeyValue objects). Be concise.
Comments